We would like to extend our sincerest apologies to this year’s CTF participants for the events that transpired on November 21. It is important that we share with the community what went wrong, what we learned, and what steps we will take to prevent such incidents from happening again in the future. Below you will find the writeup from NCPTF’s Cloud Operations team, who engineered and hosted this year’s CTF.
The conINT Organizers are currently working to build a fresh set of challenges in order to host a “redo” CTF as we have a number of prizes in our inventory to give out. Unfortunately, due to the holidays, scheduling is difficult as we want to maximize participation in the event. We will share news soon on the new CTF date, as well as registration information. As a courtesy to those who attempted to participate in the first iteration of this year’s CTF, we will provide a code to allow for free registration. Please stay tuned to our social media for further announcements for the 2021 CTF Redux.
Background
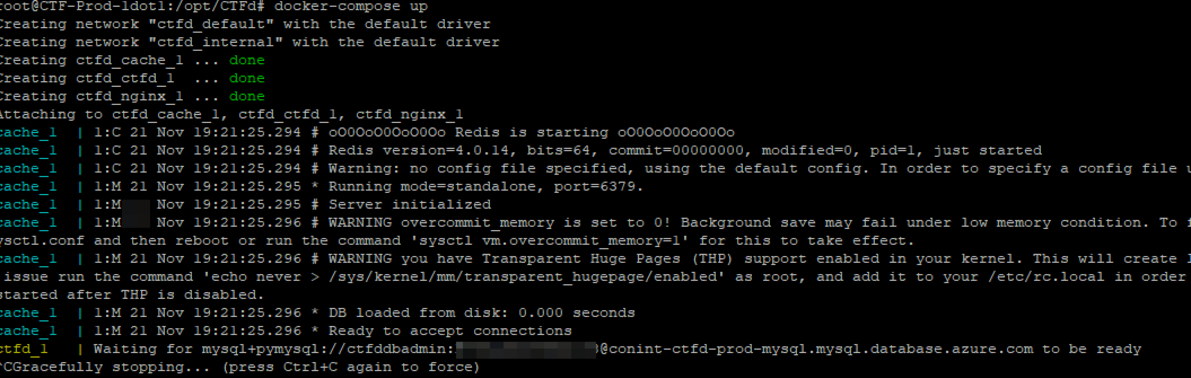
To host this conINT CTF, we utilized an open source project called CTFd. CTFd has multiple setup styles, but the container-based solution is the one most recommended by its developers. We deployed a single instance of it some time before conINT in order to build the challenges. It has been running for weeks with no errors or issues. However, this was our development and build instance. Our development server was a 1 CPU, 1 GB RAM instance, suitable for making the challenges, however, we knew we wanted something more robust for conINT.
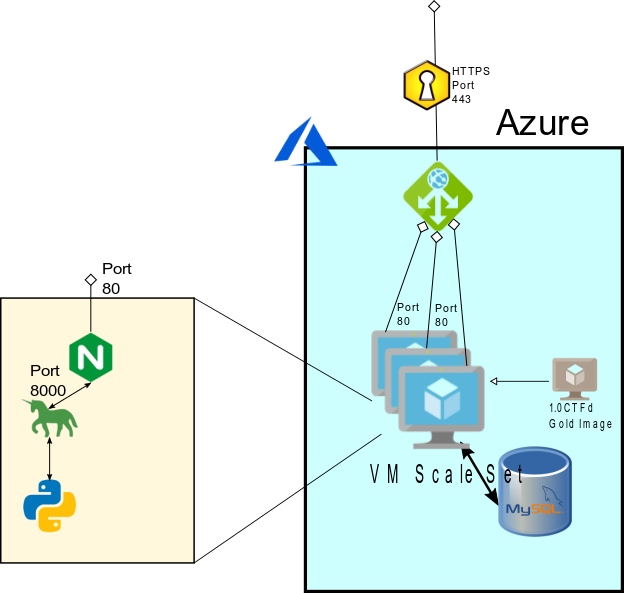
CTFd is functionally built as follows:
The fundamentally important piece is that the datastore is on the MySQL database, and it’s all locked into a given container. HTTPS, multiple containers, and everything else is left as an exercise to the infrastructure team. Also, it should be noted, passwords and usernames have been sanitized from the above screenshot.
Production Infrastructure
To build the more resilient infrastructure for conINT, we made some changes to the overall infrastructure. We wanted to have multiple front-end instances running, but all linked to the same backend data layer. To do this, we needed a single backend. We deployed a Burstable Azure MySQL database as the resilient overall data store for the event, changed the connection string the docker-compose file, and removed the database container.
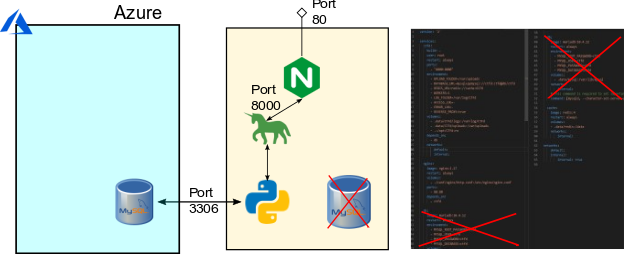
We did elect to use the new Burstable Database to save on cost, while still allowing for elasticity as the competition went on. Following this, we built a single Virtual Machine Image for CTFd that connected to the Azure Database, captured this virtual machine image as a master copy, and placed the master copy behind a Virtual Machine Scale Set. The Virtual Machines configured were 2 CPU, 4 GB Ram, in order to handle the increased load.
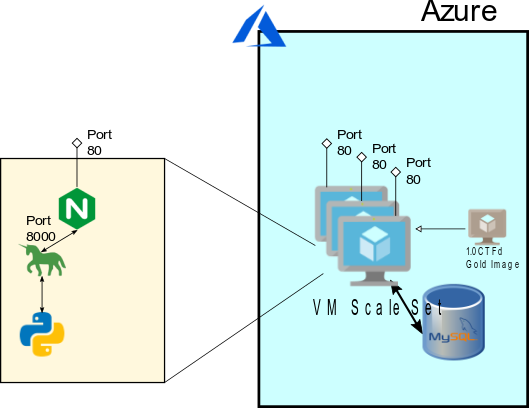
We set the scaling factor for the Virtual Machines to spin up more machines when any of them exceeded 75% CPU utilization, and downscale if they all were below 25% utilization. In front of this, we placed an Azure Application Gateway, in order to balance the load between any machines in the Virtual Machine Scale Set. The Application Gateway was set to scale as well, based on ability to Load Balance. Finally, we assigned an HTTPS certificate to the Application Gateway, and re-routed all traffic from HTTP to HTTPS.
From our chair, every element of the solution was set to auto-scale with load, so we did not see any concerns around hosting the conINT CTF.
What Happened?
We noticed shortly after the competition started that users were encountering latency and errors. We had 2 instances of the CTF VMs up initially, and expected scaling to increase as users signed on. To our surprise, no auto-scaling events had occurred. While we were investigating errors, we disabled the auto-scaling and manually upscaled. This resulted in slightly better performance for participants.
Upon further investigation, it appeared that because the Virtual Machines we deployed in our scale set had more Ram and processing power, they were not hitting the CPU threshold in order to scale, and were not effectively utilizing all the resources the VMs had. We traced the problem to the fact that we had set an insufficient number of Workers for GUnicorn, a configuration setting in the Docker-Compose file. We realized we could increase the number of workers, leave all other elements the same, and users would experience better performance. The infrastructure team’s plan was to build a 1.1 Gold Image, instantiate 3 new VMs with the 1.1 image, and then bleed the connections from the 1.0 image through the Application Gateway until users were only using the VMs with the higher worker count. The change was supposed to be seamless to the users, particularly since the data store for all the instances was the same. We could have continued to auto-scale the less-efficient systems, but we had no reason to believe that any of the manipulation we were going to be doing on the backend would be destructive.
We began to build the 1.1 image, but in order to do so, we needed to start a fresh container with CTFd, against our current backend database. Unfortunately, in starting a fresh CTFd container, as opposed to one from our pre-built image, appears to have a command that initializes the database, even if there is already currently data in it. So when the Ops team in the background do a fresh “Docker-Compose up” with the better configuration, the database containing the data that everyone was currently working in was corrupted.
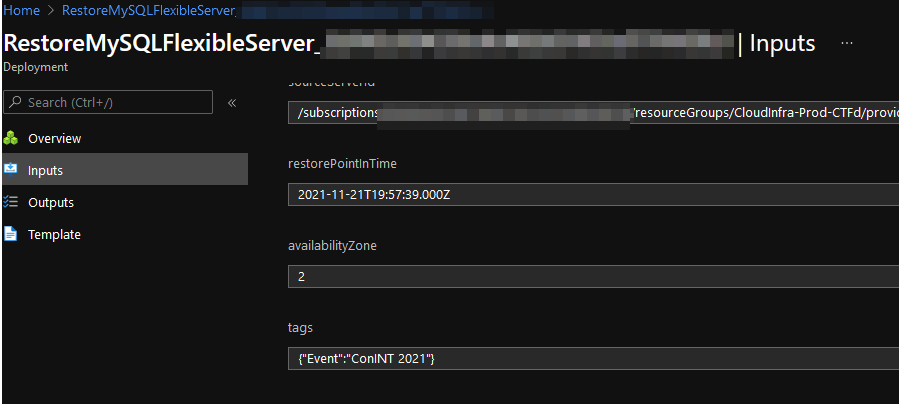
We immediately stopped what we were doing, and started to do a database restore. Azure takes Point-in-Time backups very regularly, and the most recent one was only five minutes before the database corruption. Unfortunately, you cannot restore the database straight back to the same location, you have to make a restored copy. This restore appeared to go successfully. Unfortunately, you cannot rename databases in Azure at this time, so in order to utilize the 1.0 image we already had (with the hard-coded database connection string), we needed the restored database to be in the same location as the original database. This necessitated deleting the original Prod Database, and restoring the restored copy back to the original copy.

Unfortunately, for reasons that are not clear, the ConINT-Prod-Db-Restored database from approximately 2:30pm did not contain any of the data from the users. Even more unfortunately, because we needed to put it in the same place as the original database, we had no way of doing a post-mortem of why the database restore was unsuccessful. This meant there was a total data loss of all Db Records.
Lessons Learned
- Any solution that we implement involving connection strings will have one more layer of abstraction, so we will be able to make a DNS change independent of Azure and re-route traffic.
- More comprehensive Dev environment, so changes do not impact production
- Load balancing to determine any other issues related to auto-scaling and bounding
- Thoroughly vet restored backups before removing main source.
We take full responsibility, and deeply appreciate everyone’s patience and civility while we worked on the issues. We are taking this learning event seriously, and will make every effort to ensure that the challenges experienced during this year’s CTF do not occur again.